Things Cloud DataHub 概要
このセクションでは、ドキュメントの構造を概説し、Things Cloud DataHubとそのコンセプトの概要を説明します。
このセクションでは、ドキュメントの構造を概説し、Things Cloud DataHubとそのコンセプトの概要を説明します。
次のセクションでは、Things Cloud DataHubのすべての機能について詳しく説明します。
このドキュメントの内容の概要は、次の通りです。
| セクション | 内容 |
|---|---|
| Things Cloud DataHub の利用を開始する | Things Cloud DataHub コンソールにログインし、 UI 機能の概要を確認します |
| Things Cloud DataHubのセットアップ | Things Cloud DataHub と、 そのコンポーネントのセットアップ方法を説明します |
| Things Cloud DataHubでの作業 | オフロードパイプラインを管理し、 オフロード結果のクエリする方法を説明します |
| Things Cloud DataHubの操作方法 | 管理タスクを実行する方法を説明します |
| Things CloudDataHubと他の製品の統合 | Things Cloud Things Cloud DataHub を
他の製品と統合する方法を学びます |
変更ログ には、機能、変更、その他の関連情報の概要が記載されています。
Things Cloud プラットフォームを使用すると、さまざまなデバイスを管理および監視できます。これらのデバイスから送信されたデータはThings Cloud のオペレーショナルストアに保存され、(データ保持設定に基づいて)古いデータは削除されます。Things Cloud OpenAPI仕様 で説明されているとおり、最新のデバイスデータに対してアドホッククエリを実行するために、Things Cloud はREST API を提供します。
シンプルなアドホッククエリに加えて、さまざまなユースケースでは、将来的に長期間の動作を考慮した、デバイスデータに対するより高度な分析クエリが必要です。Things Cloud DataHub は、この目的のために設計されたツールです。
Things Cloud DataHub を使用すると、次のような既存のツールとアプリケーションをThings Cloud に接続できます。
Things Cloud DataHub アプリケーションの主な機能は次のとおりです。
次の図は、基本的なワークフローを示しています。
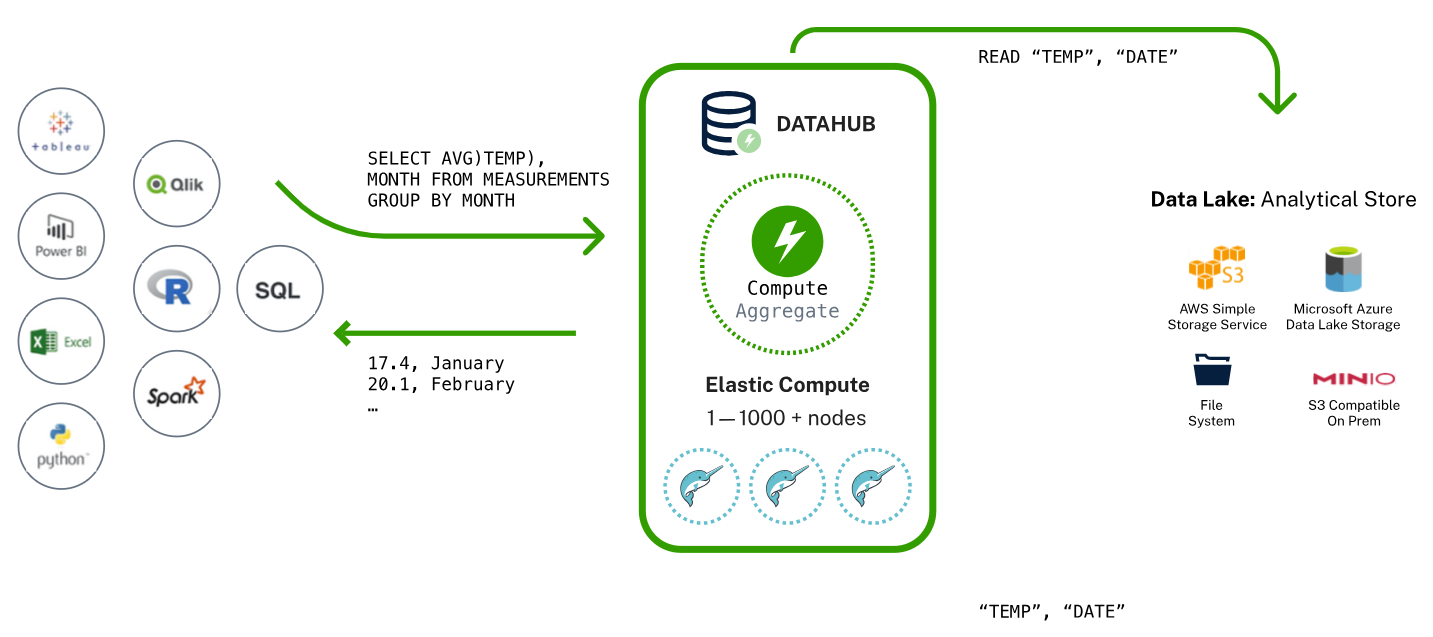
Things Cloud の中心的なコンポーネントは、上記の2つの目的に使用される分散SQLエンジンである、Dremioです。これは、上記の二つの目的のために使用されます。Dremio は、JDBC、ODBC、およびREST経由でアクセスできるSQL APIを提供しています。オペレーショナルストアからデータを抽出し、データレイクへの書き込みおよび読み取りを行うETL(抽出・変換・ロード)パイプラインを担当しています。
ユーザーがSQLクエリを送信すると、データレイクのデータに対してクエリが実行されます。 したがって、Things Cloud オペレーショナルストアはクエリ処理中にアクセスされず、オペレーショナルストアは、データを抽出するために通常のETL処理時にのみアクセスされます。Things Cloud DataHubは、これらの ETL プロセスを管理し、定期的に確実に実行します。
次の表は、このドキュメント全体で使用される主な用語をまとめたものです。
| コンポーネント | 説明 |
|---|---|
| Things Cloud DataHub | Things Cloud のオペレーショナルストアからデータレイクへのデータオフロード を行い、データレイクの内容をクエリするための Things Cloud アプリケーション。 定期的なオフロードをトリガーするためのスケジューラコンポーネント (マイクロサービスとしてデプロイ)およびオフロードパイプラインの定義、 管理、監視を行うUIコンポーネント(Webアプリケーションとしてデプロイ)です。 |
| Things Cloudオペレーショナルストア | アラーム、イベント、インベントリ、メジャーメントなど、すべてのデータがいわゆる ベースコレクションに保存されるThings Cloudの内部データストアです。 |
| Dremio | Things Cloud オペレーショナルストアからデータを抽出し、データレイクへの書き込みおよび読み取りを行う内部SQLエンジンです。 |
| データレイク | ADLS Gen2/Azure Storage(Azure)、S3(Amazon)、NASに基づいてオフロードされたデータのストレージコンテナです。 |
オフロードとは、データをThings Cloud のオペレーショナルストアからデータレイクに移動し次を行います。
起点は、メジャーメントコレクションなど、データレイクにオフロードされる基本的なThings Cloud ベースコレクションの1つとなります。このコレクションのオフロードパイプラインが構成設定されて開始されると、いくつかのアクションが実行されます。
オフロードジョブが実行されると、コレクションのコンテンツがオフロードされます。Things Cloudオペレーショナルストアのドキュメントベースの要素は、フラット化され、関係する行にマッピングされることで、リレーショナル形式に変換されます。
time、source、id、type などの標準属性セットを各エンティティから自動的に抽出し、それをデータレイクのテーブルの列に変換します。さらには、メジャーメントフラグメントの内容もテーブルの列に自動的に変換されます。非標準フィールドも限定的にオフロードできます。オフロードジョブの設定 では、この変換に関する詳細や例が提供されています。これらの抽出および変換手順を経ると、フラット化されたデータはデータレイクのParquetファイルに保存されます。Apache Parquetとは、圧縮と効率的なデータ取得を可能にする列基盤のストレージ形式です。パフォーマンス上の理由から、これらのParquetファイルは、一時的な階層に基づいたフォルダー構造で管理されます。一時的な階層を使用する理由は、ほとんどの分析クエリには、たとえば先月の平均油圧を計算、などの一時的バックグラウンドがあるためです。Parquetファイルのコンパクトなレイアウトを確保するために、Things Cloud DataHubコンソールはこれらのファイルに対してバックグラウンドで定期的に圧縮アルゴリズムも実行します。データレイクに時間ベースの階層方式でデータが格納される場合、Things Cloud DataHubはパーティションを効率的に整理できます。さらに、構造を明示的に活用してクエリのパフォーマンスを向上させることができます。
Things Cloud DataHubのスケジューラは、定期的にオフロードパイプラインを実行します。 UIでは、各構成設定の横に実行スケジュールが表示されます。それぞれの実行内では、新しく到着したデータがThings Cloudコレクションから抽出され、上述と同じ方法で変換および保存されます。これらの増分オフロードタスクは、コレクションからの損失および重複のないオフロードを保証するように設計されています。たとえば、1つのオフロード実行が失敗した場合、次の実行では、失敗した実行が処理すべき分が自動的に増分として取得されます。
オフロードパイプラインごとに、データレイク内の対応するデータフォルダーを指すターゲットテーブルがDremioに作成されます。オフロードされたデータに対して Dremio でクエリを実行する場合は、これらの ターゲットテーブル を使用する必要があります。